BLM1: A Boundless Large Model for Cross-Space, Cross-Task, and Cross-Embodiment Learning
Abstract
Multimodal large language models (MLLMs) have advanced vision–language reasoning and are increasingly deployed in embodied agents. However, significant limitations remain: MLLMs generalize poorly across digital–physical spaces and embodiments; vision–language–action models (VLAs) produce low-level actions yet lack robust high-level embodied reasoning; and most embodied large language models (ELLMs) are constrained to digital-space with poor generalization to physical world. Thus, unified models that operate seamlessly across digital and physical spaces while generalizing across embodiments and tasks remain absent. We introduce the Boundless Large Model (BLM1), a multimodal spatial foundation model that preserves instruction following and reasoning, incorporates embodied knowledge, and supports robust cross-embodiment control. BLM1 integrates three key capabilities—cross-space transfer, cross-task learning, and cross-embodiment generalization—via a two-stage training paradigm. Stage I injects embodied knowledge into the MLLM through curated digital corpora while maintaining language competence. Stage II trains a policy module through an intent-bridging interface that extracts high-level semantics from the MLLM to guide control, without fine-tuning the MLLM backbone. This process is supported by a self-collected cross-embodiment demonstration suite spanning four robot embodiments and six progressively challenging tasks. Evaluations across digital and physical benchmarks show that a single BLM1 instance outperforms four model families—MLLMs, ELLMs, VLAs, and GMLMs—achieving ∼6% gains in digital tasks and ∼3% in physical tasks.
Performance
Digital-Space Benchmarks
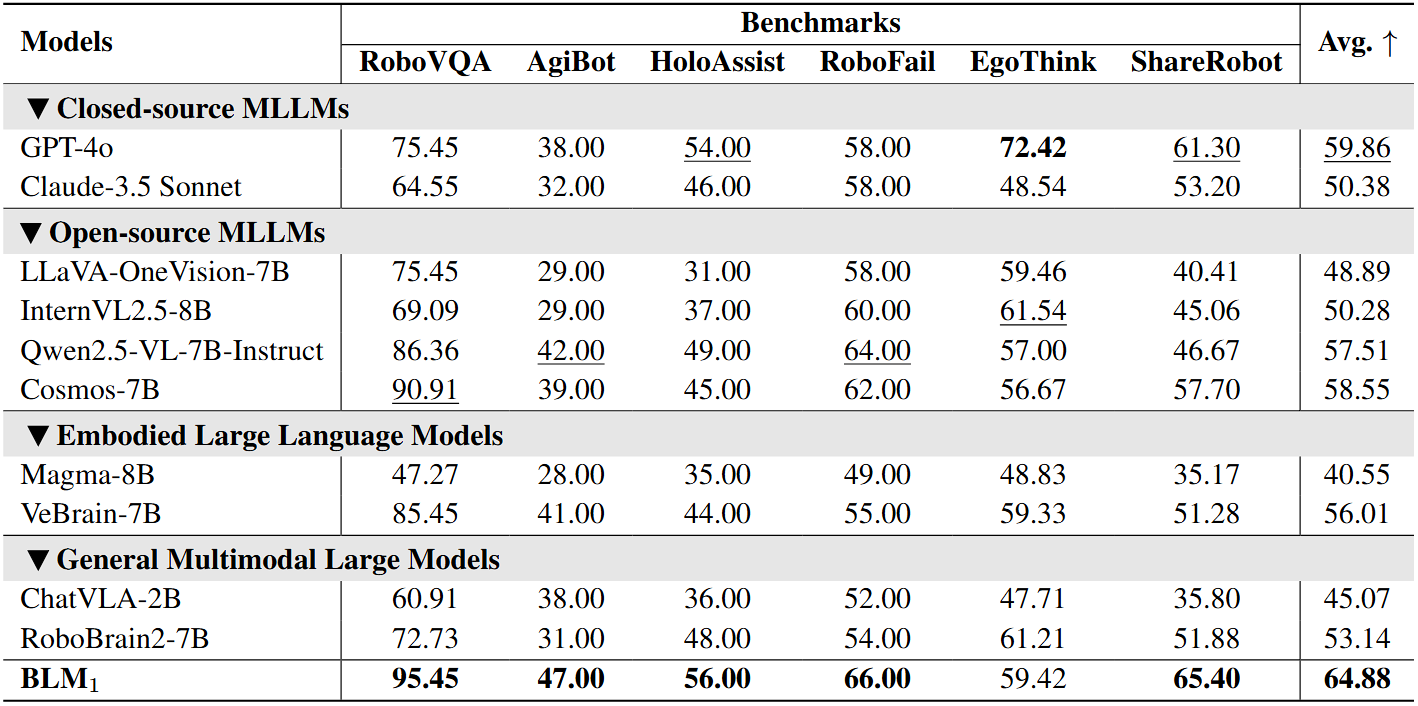
Comparison with existing closed/open-source MLLMs, embodied large language models and general multimodal large models on digital-space benchmarks.
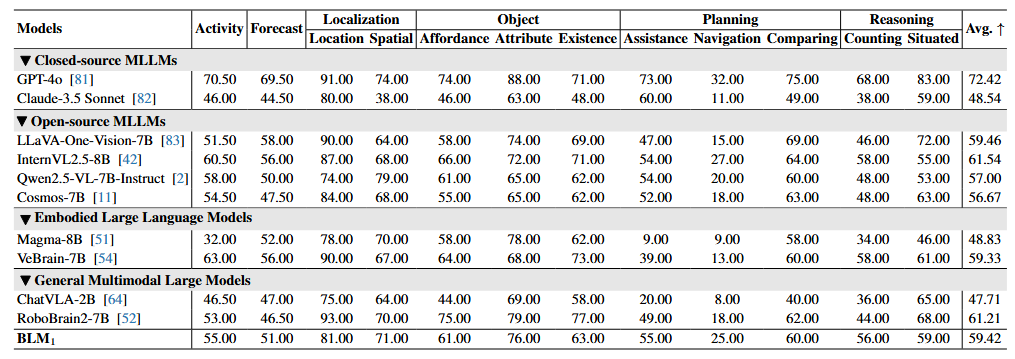
Comparison with existing MLLMs, ELLMs and GMLMs on EgoThink.
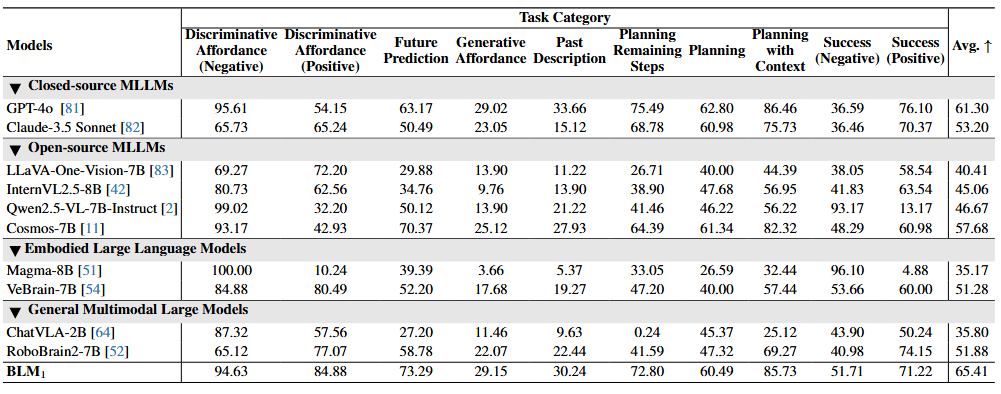
Comparison with existing MLLMs, ELLMs and GMLMs on ShareRobot.
Physical-Space Benchmarks
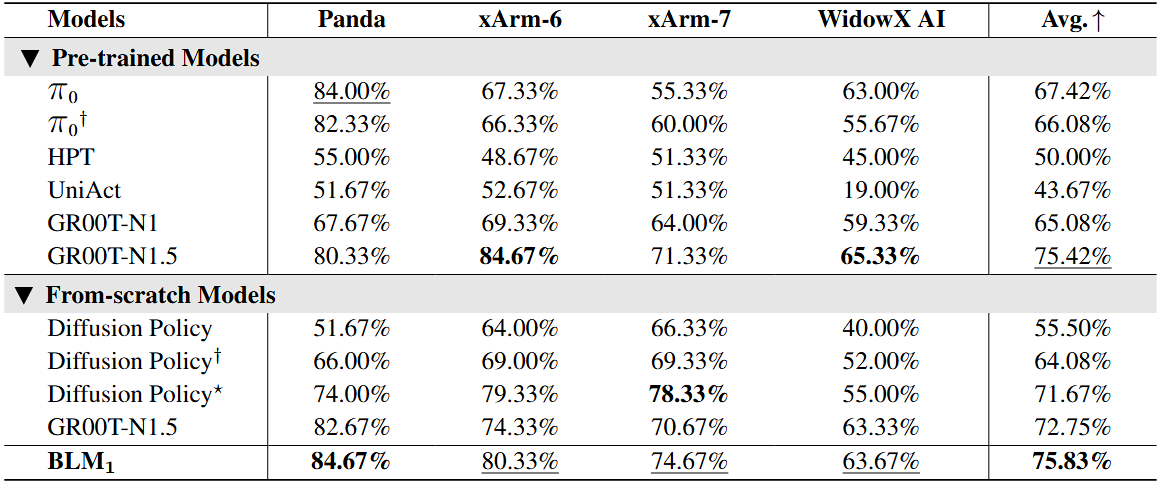
Comparison with existing VLAs on Physical-Space benchmarks. † denotes the training of independent models on four robots, with each model evaluated across six tasks. ⋆ denotes training independent models for each of the six tasks associated with four robots (24 models in total), with evaluation on the corresponding tasks for each robot.
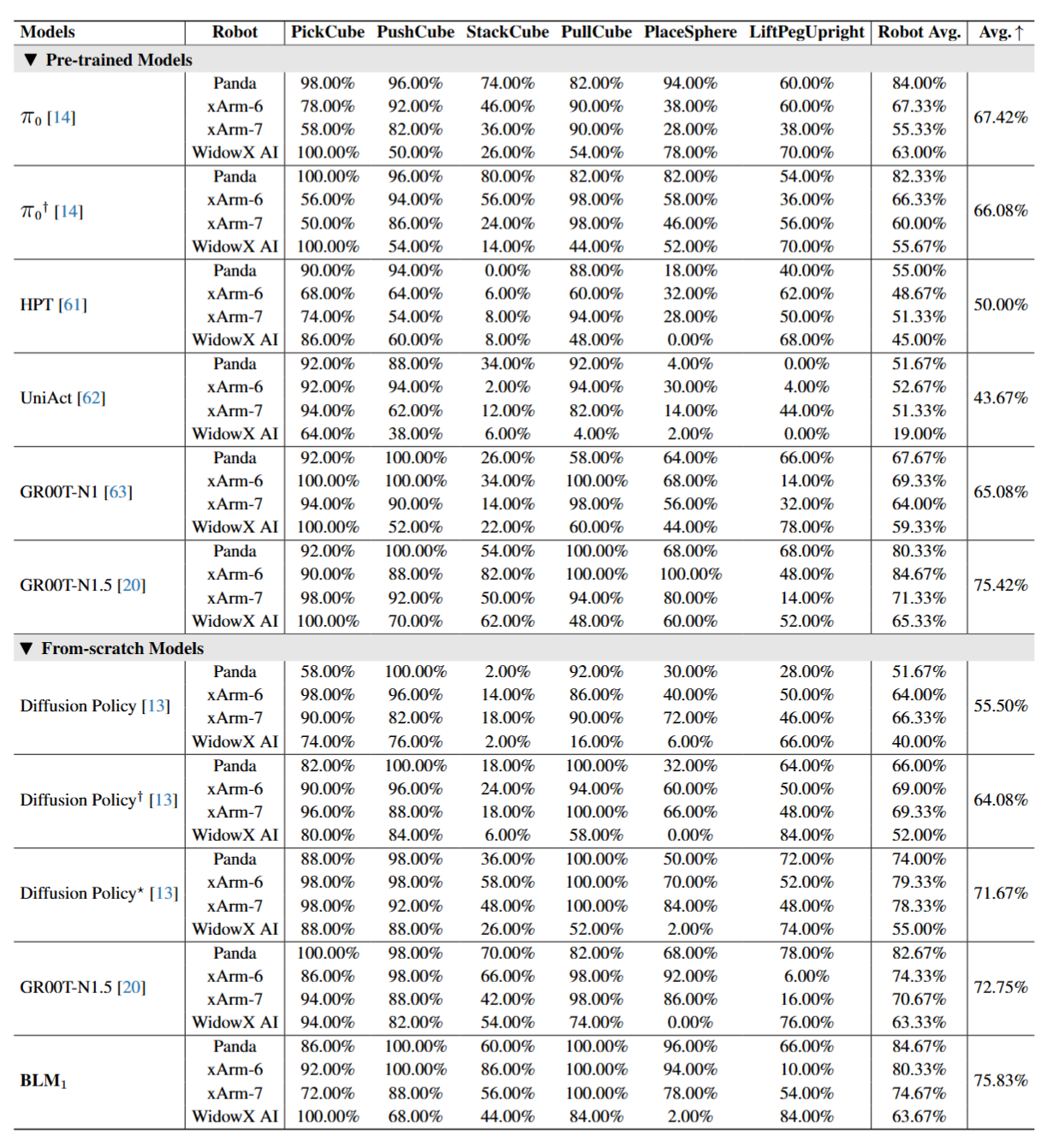
Detailed comparison with existing VLAs on Physical-Space benchmarks.
Model Architecture
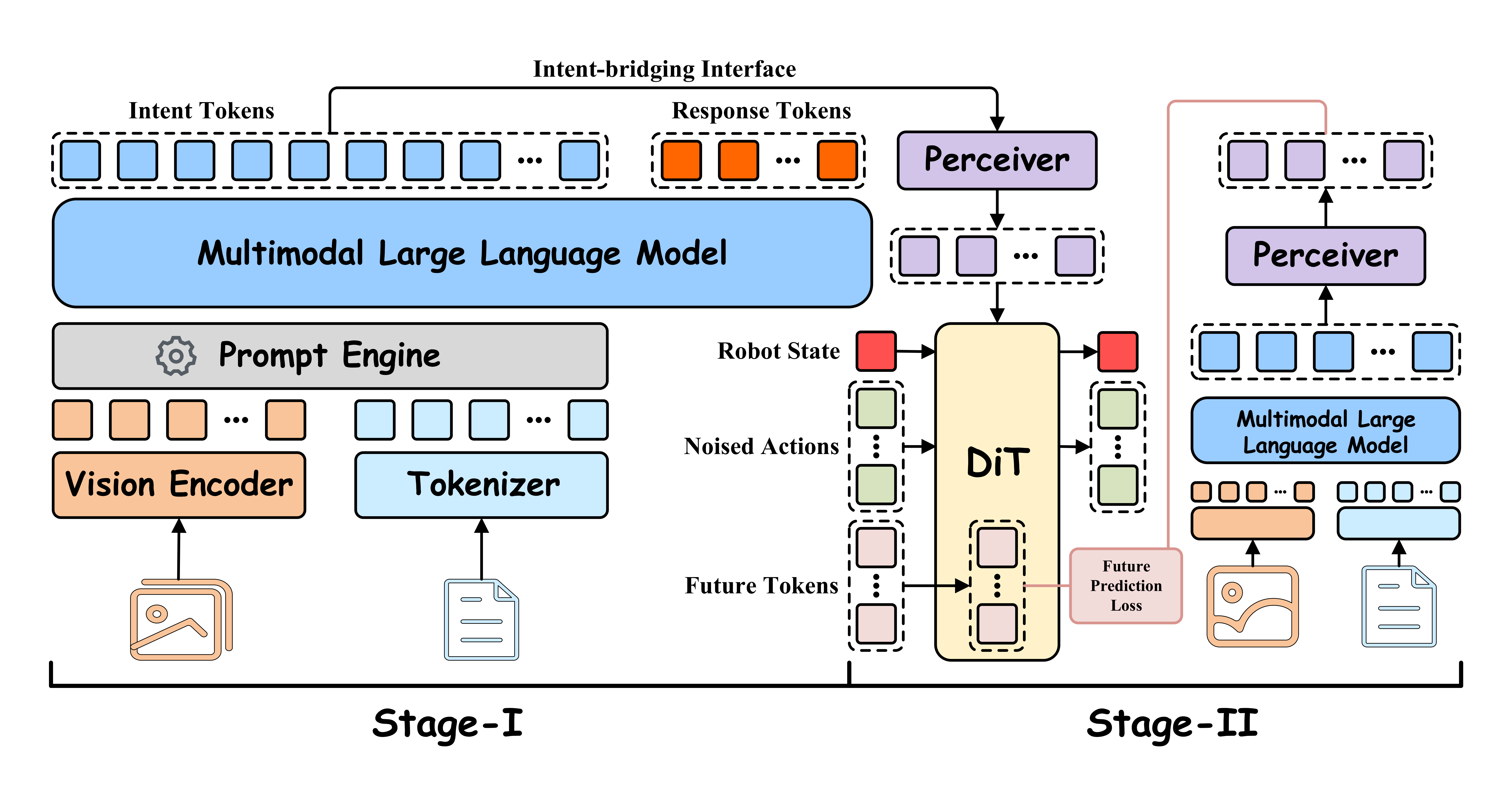
The main framework of BLM1. Multimodal inputs are first encoded and fused by a prompt engine, then passed to the MLLM backbone. BLM1 follows a two-stage training paradigm. In Stage I, the model undergoes supervised fine-tuning on digital-space tasks to acquire embodied knowledge while preserving instruction-following capabilities. Stage II introduces an intent-bridging interface that connects the MLLM to a Diffusion Transformer policy head. This stage is trained using robot states, noisy actions, and a future-prediction loss. The result is a single unified model capable of handling both digital and physical tasks, enabling three boundless capabilities: cross-space transfer, cross-task learning, and cross-embodiment generalization.
Multimodal Spatial Data Engine
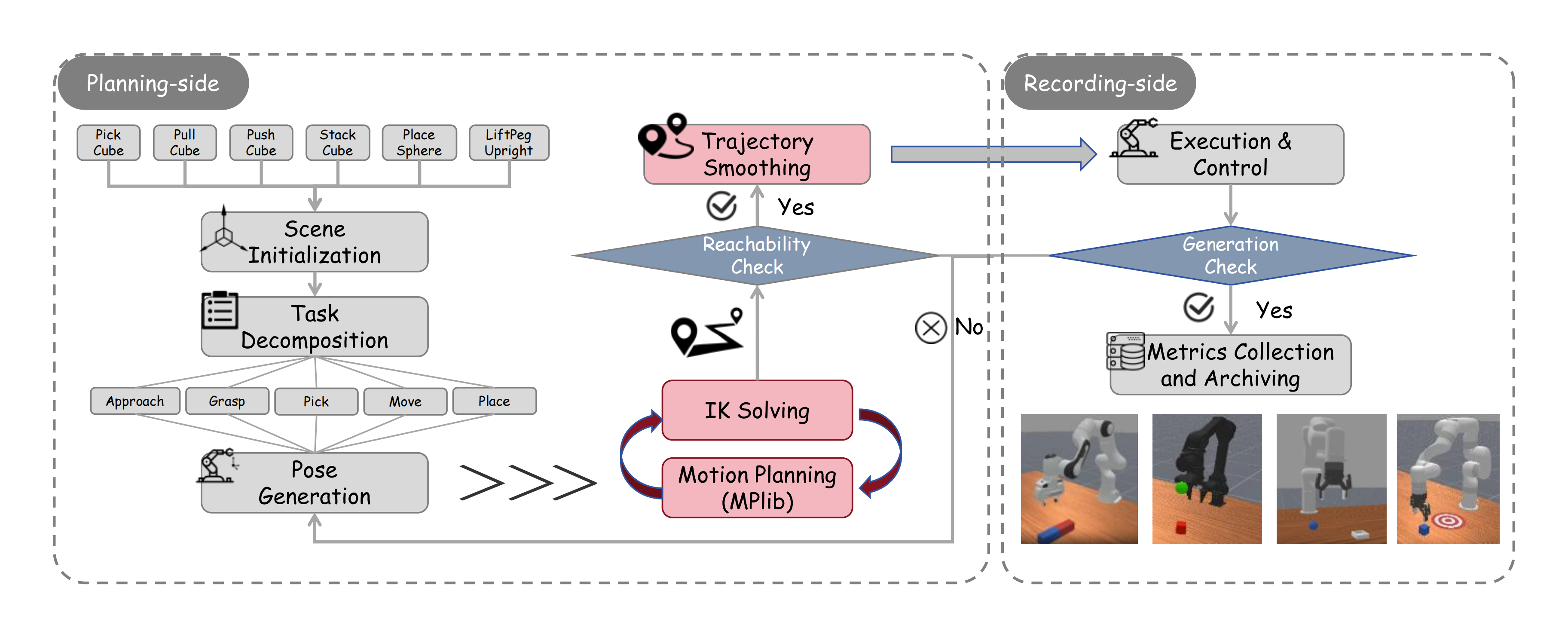
Our data collection pipeline is built upon the ManiSkill framework and is divided into two main stages: planning and recording. In the planning stage, we adopt a unified strategy of high-level skills, key-pose guidance and motion planning execution. Specifically, we first select a sampling task from six predefined robotic manipulation tasks and initialize the corresponding scene. Next, inspired by the concept of keyframes, each task is decomposed into a series of primitive actions (e.g., approaching, grasping, moving), and a target end-effector pose is generated for each primitive. For every target pose, we solve the Inverse Kinematics (IK) to obtain joint configurations and perform feasibility checks, including joint limits, self-collision, and environment collision. If infeasible, resampling or switching to alternative poses is applied. For feasible poses, we conduct path planning and trajectory smoothing before moving to the recording stage. In the recording stage, the robot executes the task either through joint-space trajectories or end-effector pose tracking, while success is continuously monitored. If a failure occurs, the system performs fine adjustments or rollback operations; if successful, the relevant states and trajectories are recorded, completing the data collection process.
Demos

Comparisons

Example of results comparison in multiple-choice questions.
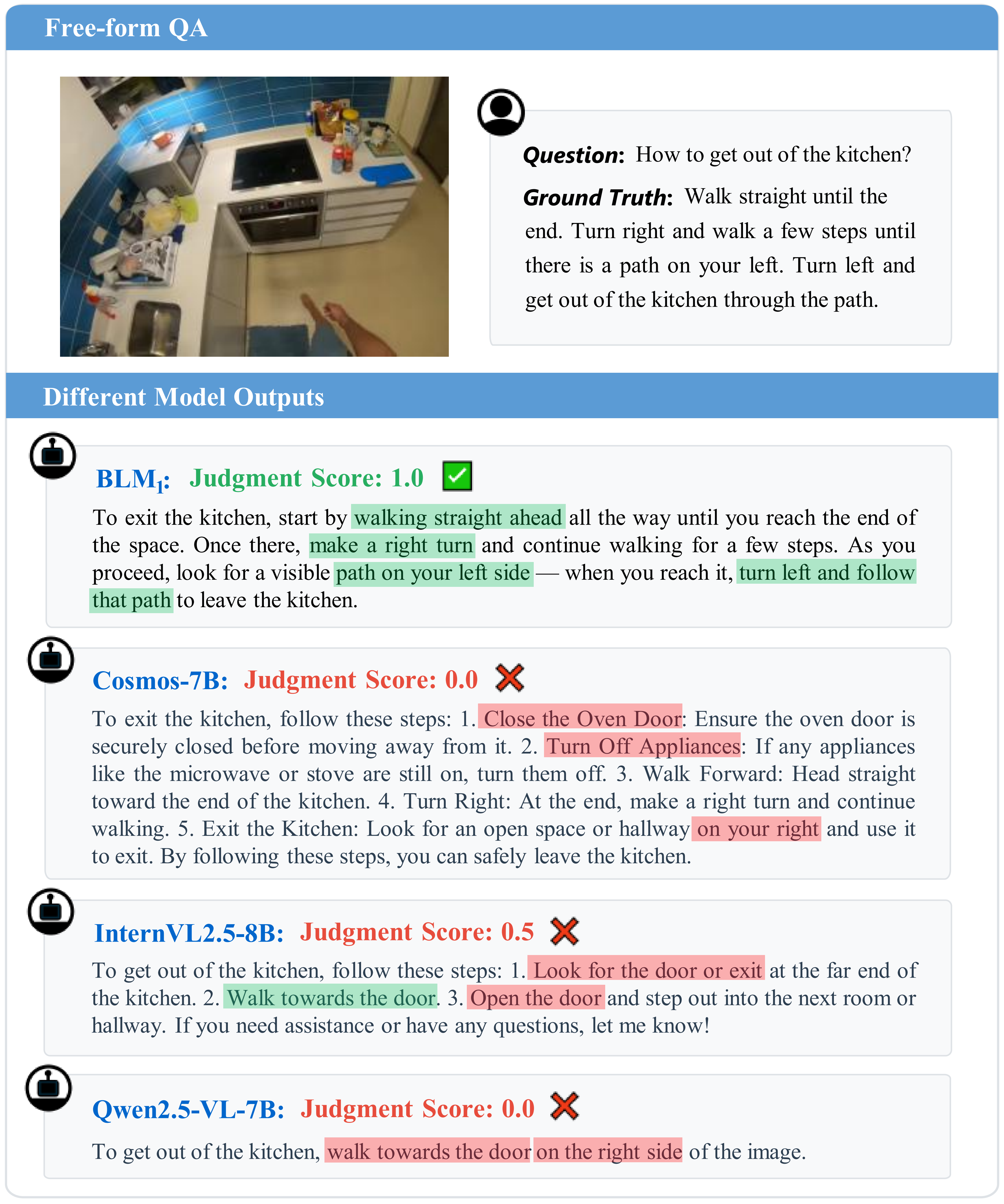
Example of results comparison in free-form QA.
Citation
If you find this project useful, please consider citing our paper.
@article{
BLM-1,
title={BLM$_1$: A Boundless Large Model for Cross-Space, Cross-Task, and Cross-Embodiment Learning},
author={Wentao Tan, Bowen Wang, Heng Zhi, Chenyu Liu, Zhe Li, Jian Liu, Zenrong Lin, Yukun Dai, Yipeng Chen, Wenjie Yang, Enci Xie, Hao Xue, Baixu Ji, Chen Xu, Zhibin Wang, Tianshi Wang, Lei Zhu, Heng Tao Shen},
year={2025}
}Acknowledgement
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.